规则引擎介绍
在数据接入过程中,还需要对数据进行清洗和处理。唯简M³Meta平品提供了分布式规则处理引擎,可以在整个数据中台集群范围内实现对队列数据的复杂规则操作,包括数据清洗、数据计算、格式转换、数据丰富、数据关联、日志分词、数据标签等。
数据清洗
数据清洗的任务是过滤那些不符合要求的数据,不符合要求的数据主要是有不完整的数据、错误的数据和重复的数据三大类。
- 不完整的数据,是一些应该有的信息缺失,如供名称或客户基本信息的缺失、业务系统中主表与明细表不能匹配等。补全后才写入数据仓库。
- 错误的数据,产生原因是业务系统不够健全,在接收输入后没有进行判断直接写入后台数据库造成的,比如数值数据输成全角数字字符、字符串数据后面有一个回车、日期格式不正确、日期越界等。这种数据修改以后再入库。
- 重复的数据,特别是维表中比较常见,将重复的数据的记录所有字段导出来,确认并做合并整理。
数据处理
数据处理就是将数据进行转换或归并,从而构成一个适合数据处理的描述形式。数据处理包含以下处理内容。
平滑处理
帮助除去数据中的噪声,主要技术方法有 Bin 方法、聚类方法和回归方法。
合计处理
对数据进行总结或合计操作。例如,每天的数据经过合计操作可以获得每月或每年的总额。这一操作常用于构造数据立方或对数据进行多粒度的分析。
数据泛化处理
用更抽象(更高层次)的概念来取代低层次或数据层的数据对象。
例如,街道属性可以泛化到更高层次的概念,如城市、国家,数值型的属性,如年龄属性,可以映射到更高层次的概念,如年轻、中年和老年。
规格化处理
规格化处理就是将一个属性取值范围投射到一个特定范围之内,以消除数值型属性因大小不一而造成挖掘结果的偏差,常常用于神经网络、基于距离计算的最近邻分类和聚类挖掘的数据预处理。规格化处理将有关属性数据按比例投射到特定的小范围之中。例如,将属性值映射到 0 到 1 范围内。
属性构造处理
根据已有属性集构造新的属性,以帮助数据处理过程。属性构造方法可以利用已有属性集构造出新的属性,并将其加入到现有属性集合中以挖掘更深层次的模式知识,提高挖掘结果准确性。
例如,根据宽、高属性,可以构造一个新属性(面积)。构造合适的属性能够减少学习构造决策树时出现的碎块情况。此外,属性结合可以帮助发现所遗漏的属性间的相互联系,而这在数据挖掘过程中是十分重要的。
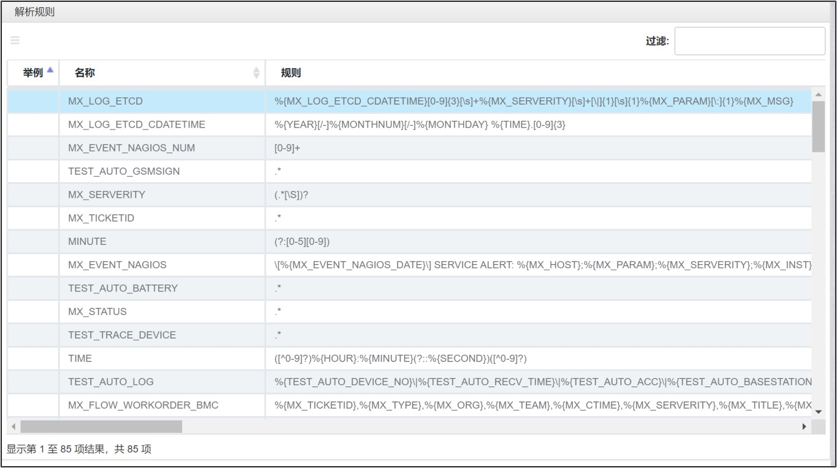
可扩展的日志分词规则
日志信息作为重要的一类运维数据,具备非结构化、数据量大的特点,M³Meta平台支持在规则中进行分词设置,满足对非结构化日志数据的快速结构化处理。
数据分发
数据处理规则引擎提供的forward转发功能,将数据转发至其他队则继续进行处理,也支持将数据通过转发功能通过KAFKA、NATS等队列服务转发至其他第三方系统。
Cache机制
在处理规则中提供不同类型的Cache机制,包括面向分布式规则处理的全局化Cache、针对于类表的表级别本地Cache,以及针对于外表文件的文件表Cache。
全局化Cache
全局化Cache支持在分布式处理环境下,各个规则能够共用Cache空间。同时,支持设置Ttl,定义Key/Value Cache自动失效事件。
-- setvar: Set gloabl cache var
-- params: <key string>, <value any>, <ttl int>, <domain string (Optional)>
-- return: None
setvar('K1', 'V1', 0, '') -- No TTL
setvar('K1', 'V1', 30, '') -- TTL seconds
-- getvar: Get gloabl cache var
-- params: <key string>, <domain string (Optional)>
-- return: <value any>
local ret = getvar('K1', '')
-- getvars: Get all gloabl cache var
-- params: <domain string (Optional)>
-- return: <result table>
local ret = getvars('')
类表级别本地Cache
类表级别本地Cache支持将指定类表数据进行Cache,供经过此规则的数据使用。当类表数据发生变化时,需要调用方法刷新Cache通知运行规则,适合于不经常变化的Cache数据。
-- classcache: Query class cache by conditions
-- params: <class string>, <where string>
-- where: Query logic expression
-- ||
-- &&
-- = != > < >= <= ~= !~= is isnot contains
-- + -
-- * / %
-- ^
-- ( )
-- return: <result table>
local ret = classcache('/test', "id = 'ID1'")
外表文件的文件表Cache
外表文件的文件表Cache是利用外表文件定义的表结构,实现高效快速的Cache定义和查询,适合于变化较频繁,且是表结构的Cache内容,通常被应用于数据的丰富、关联等操作。
-- lookup: Lookup extend info
-- params: <extendName string>, <condition table>
-- return: <result table>
local ret = lookup('hostinfo', {key='mxsvr1'})
IBM Omnibus规则算子支持
在规则中兼容IBM omnibus监控产品算子,满足了相关数据集成的需求。
-- charcount: Returns the number of characters in a string.
-- params: <str string>
-- return: <count number>
local count = omni.charcount('ABCDE12345')
-- clear: Removes the elements of an array.
-- params: <table string>
-- return: None
clearTable = {'A', 'B', 'C'}
omni.clear(clearTable)
-- extract: Returns the part of a string (which can be a field,element, or string expression) that matches theparenthesized section of the regular expression.
-- params: <str string>, <regxp string>
-- return: <str string>
local exts = omni.extract('Access Port 123 ok', 'Port ([0-9]+)') -- exts: Port 123
-- length: Converts a numeric value into an integer.
-- params: <str string>
-- return: <len number>
local strlength = omni.length('ABCDE12345')
-- log: Enables you to log messages.
-- params: <level string>, <msg string>
-- return: None
omni.log('DEBUG', 'Value is 1')
-- match: Tests for an exact string match.
-- params: <str1 string>, <str2 string>
-- return: <ok bool>
local str = omni.match(str1, 'abc')
-- nmatch: Tests for a string match at the beginning of aspecified string.
-- params: <str string>, <prefix string>
-- return: <ok bool>
local str = omni.nmatch(str, 'a')
-- regmatch: Performs full regular expression matching of avalue in a regular expression in a string.
-- params: <str string>, <reg string>
-- return: <ok bool>
local str = omni.regmatch(str, '^Name:[0-9]')
规则开发工具
支持在线编辑规则
M³Meta中的分布式规则处理引擎为用户提供了灵活的规则定义工具,可以根据实际的数据处理需求,进行数据处理规定的定制。分布式规则处理引擎支持脚本化的处理规则编写,支持lua语言脚本嵌入。
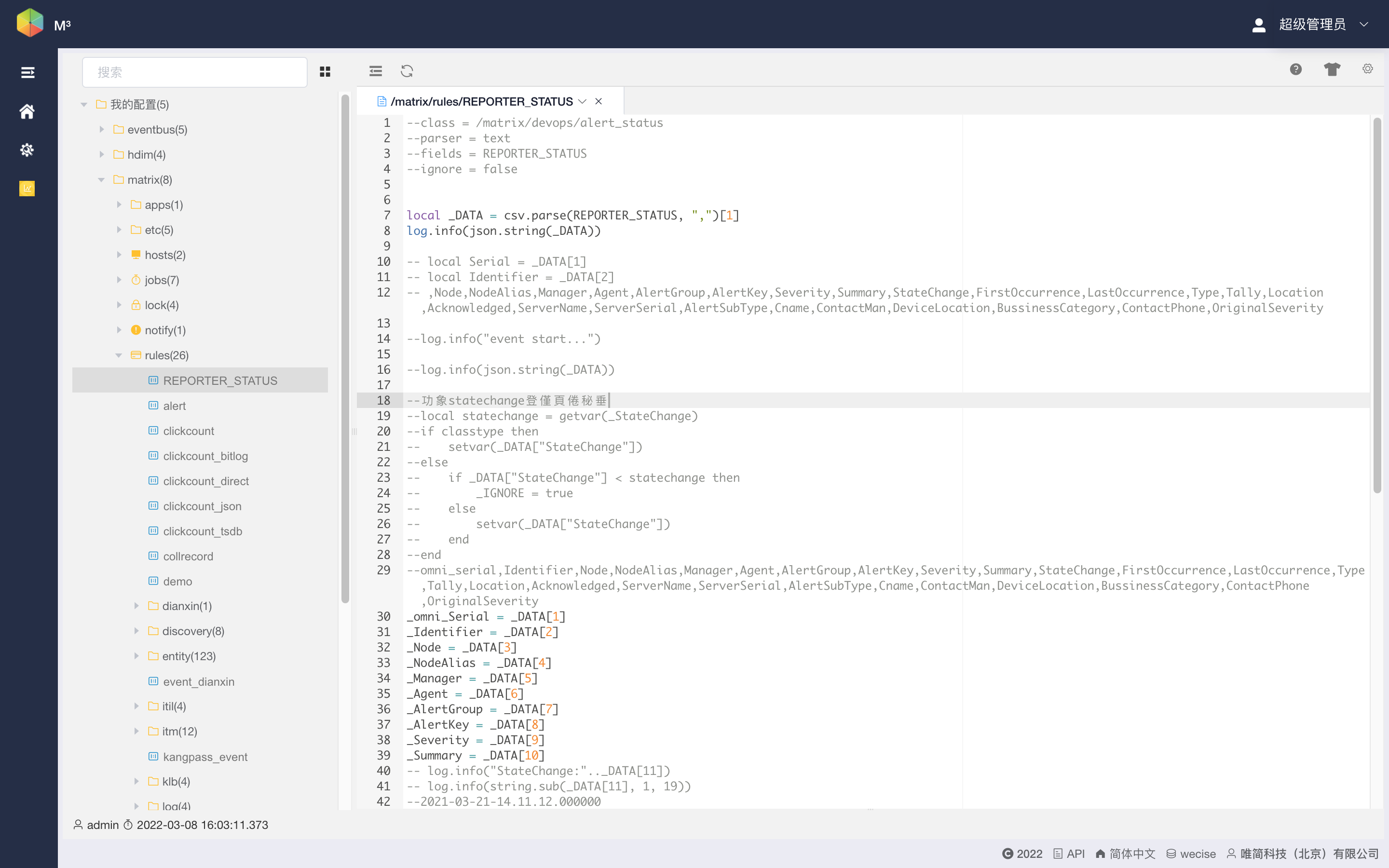
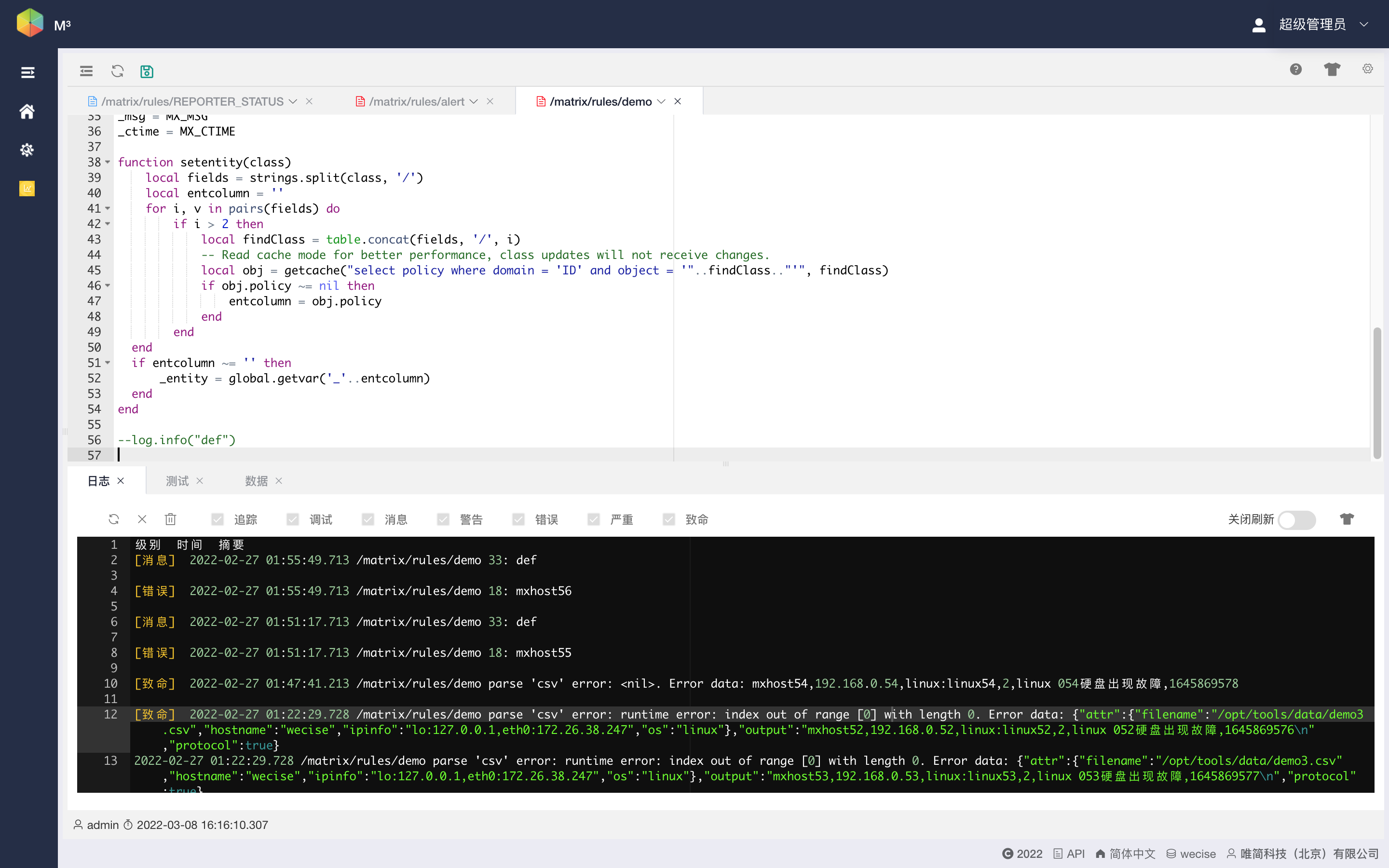
支持在线规则调试
在处理规则编写过程中,支持对规则进行在线编写,同时支持对规则进行在线debug,如图11‑88所示。此处“在线”有两个含义:一是编辑和debug工作在小应用UI上进行,二是编辑后生效或debug时无需重启相应的后台线程。